Is ReLU Dead?
In this Article, I will discuss the problem of dying Relu and how to identify them using Tensorboard
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://cdn-images-1.medium.com/max/7000/0*hXpM6p8OmBebqzbY)
This article is about identifying dead ReLU problem using TensorBoard which is a visualization toolkit for Machine Learning experiments.
What is ReLU?
ReLU stands for Rectified Linear Units. ReLU is used mainly in Artificial Neural Networks as an activation function. By default, ReLU is the most preferred activation function. The main reason for that is ReLU doesn’t suffer from Vanishing gradient problem. Mathematically ReLU can be expressed as:

Another way to express this is as follows :
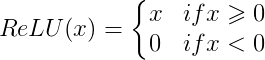
This function looks visually as :
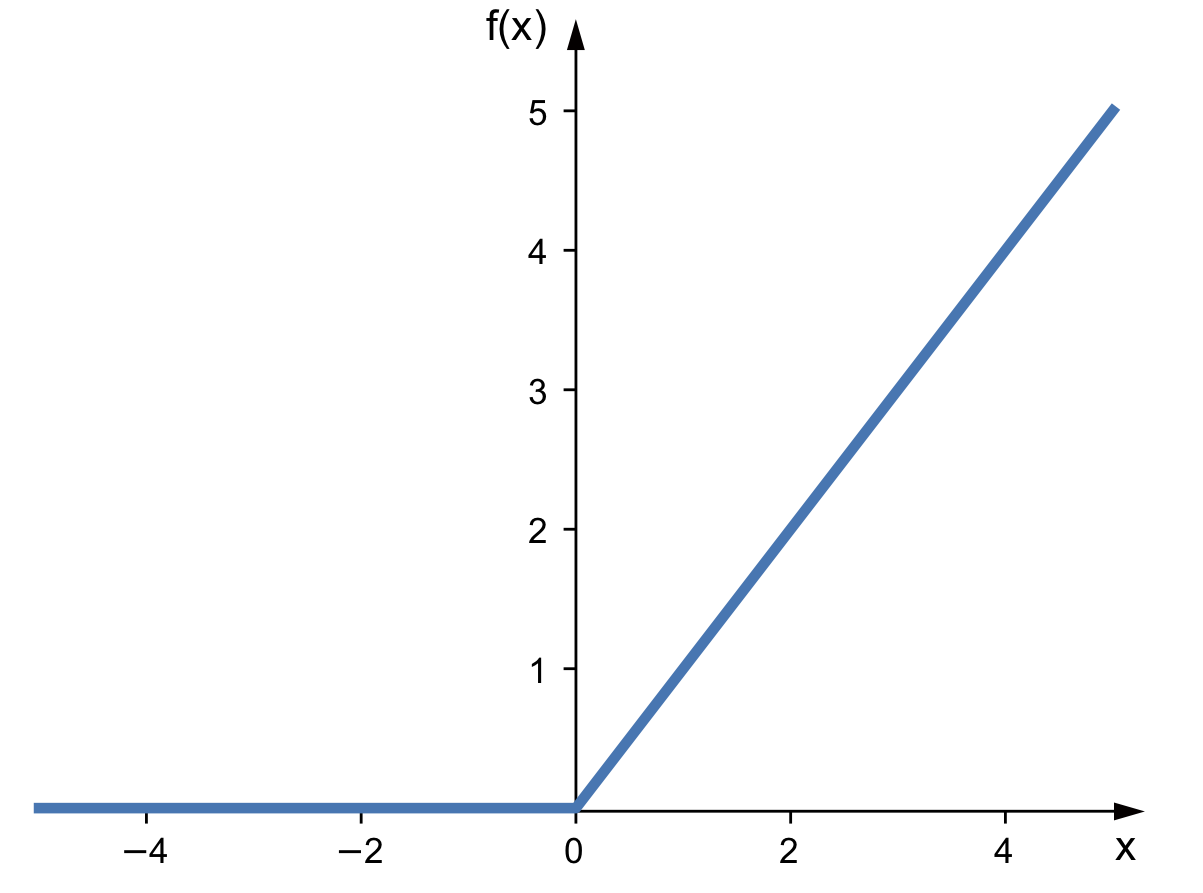
Please note that the function is not linear. The output of ReLU is non-linear.
The derivative of ReLU is :
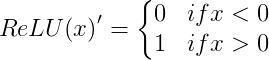
Derivative of ReLU is undefined at x=0.
What is Dying ReLU problem?
The main advantage of ReLU is that it outputs 0 and 1 thus solves the problem of Vanishing Gradient(because we don’t have to multiply extremely small values during Backpropagation). However, it has it’s own downside too. Because it outputs 0 for every negative value, a ReLU neuron might get stuck in the negative side and always output 0, and it is unlikely for it to recover. This is called as the dying ReLU problem. This is a serious problem because if a neuron is dead, then it basically learns nothing. Because of this problem, there might be the case of a large part of the network doing nothing.
Detect Dying ReLU using TensorBoard
Create a random sample using the following :
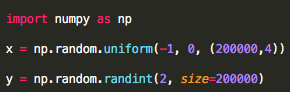
Here x is an array of size 200k x 4 with values sampled uniformly in the range (-1,0). The array is highly negative one, the kind of input that relu doesn’t like. Then split the data into train and test set with 70% of data for train and 30% for test.
Use a simple one layer Network with relu activation function. Initialize the initial weights randomly and initial bias as zero.

Now initialize TensorBoard variable. We need the gradients at each epoch, so initialize the “write_grads” = True

Now finally fit the model and in the callbacks parameter use TensorBoard variable.

Plot the training and Validation loss.


From the above two plots it’s clear that the model’s loss hasn’t improved which means that the model has stopped learning. Now use TensorBoard to visualise the gradients and output of the dense layer.
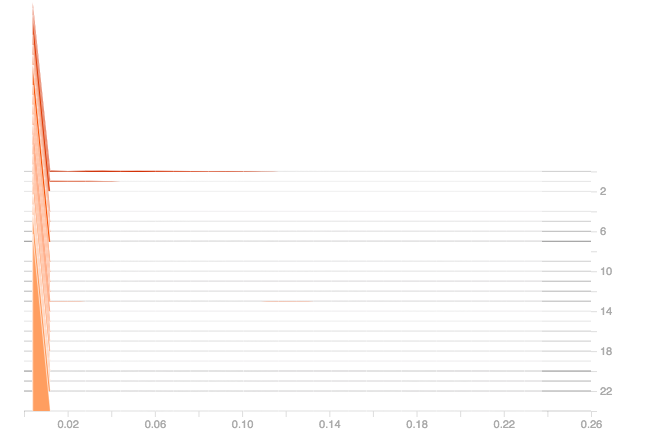
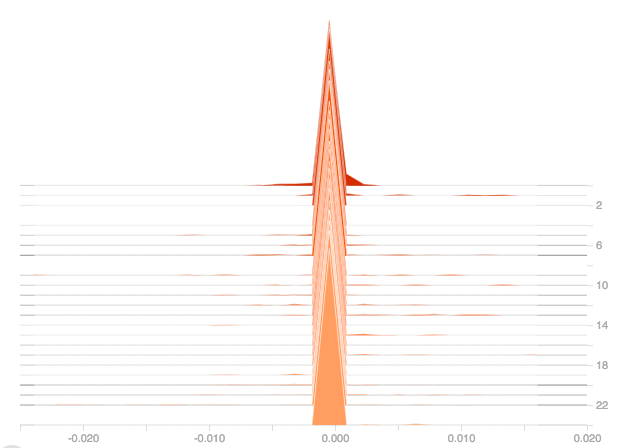
From the above two plots, it can be observed that the dense layer gradients are zero for all the epochs, and the output is also zero for the 25 epochs. From the above gradient plot, it can be seen that, once the gradient goes to zero, the model struggles to recover from this situation and is completely dead now, which can be seen from the loss graph too, as the loss doesn’t change over time which indicates that the model’s learning has stopped or model is learning nothing.
Add More Layers
I’ll now use a three hidden layer network with the same ReLU kernel and see if this problem can be solved. I’ll use the following network :

This is a three layer network with activations for all the layers set to ReLU.
Now observe the TensorBoard Gradients for all these layers:
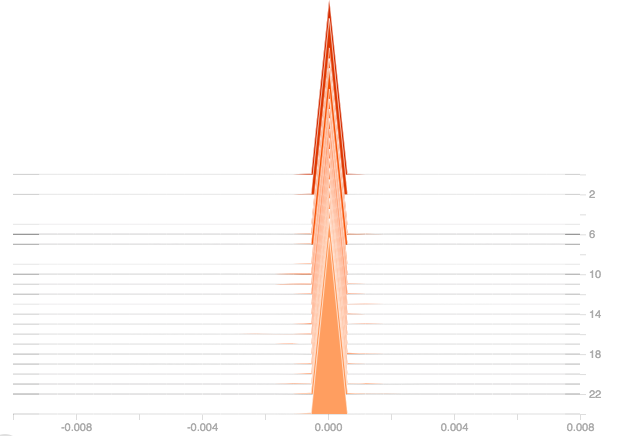
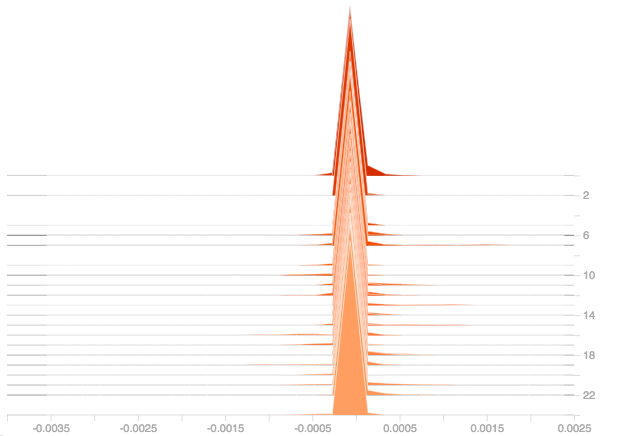
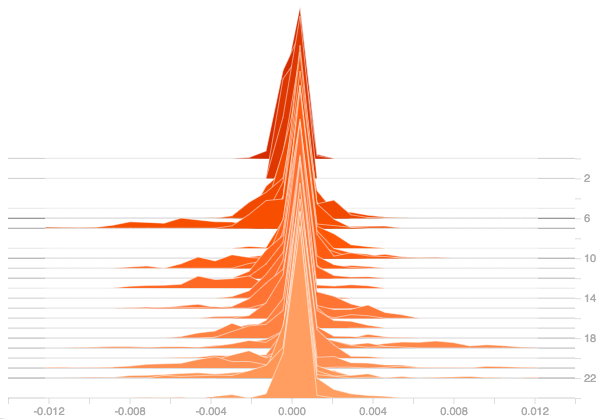
From the three plots, it can be seen that Adding more layers doesn’t solve the issue of dead ReLU as can be seen from the above plots that the gradients are still zero for all the layers and they get propagated to all the other layers in the model and hence affecting the model’s performance.
Solution?
1.Does increasing data size help?
A big NO!!. If the new data has the same distribution like the ones that are already present, then there is no use in including them in the training set. However, collecting a new dataset for the same problem may be considered as an option.
2.Does adding Dropouts help?
Dropouts have nothing to do with the output of ReLU, so adding dropout or changing dropouts have little effect on dead activations.
3.Does adding more layers help?
No, it doesn’t help to solve dying ReLU problem, which is clear from above section.
4.Does increasing the epochs help?
No, it doesn’t help too because after each epoch, the weights get updated, however, due to the dead neurons, the gradients will be zero as a result the weights will never get updated, it remains same and calculating the gradients again using the same weight will result in 0, hence this doesn’t have any impact on dead ReLU.
5.Does changing the weight initialization help?
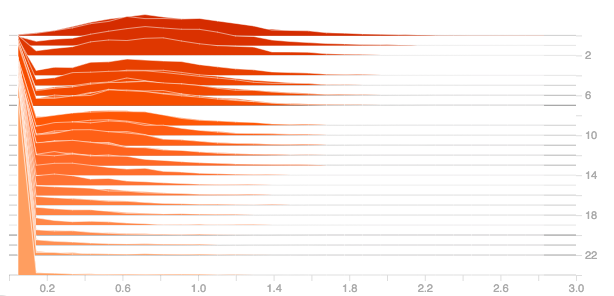
For answering this question, let’s try with different weight initializers and plot their gradients and outputs. The following it the plot of the gradients for dense layer using relu activation for the weight initializers: he_normal, he_uniform, lecun_normal and random_uniform.
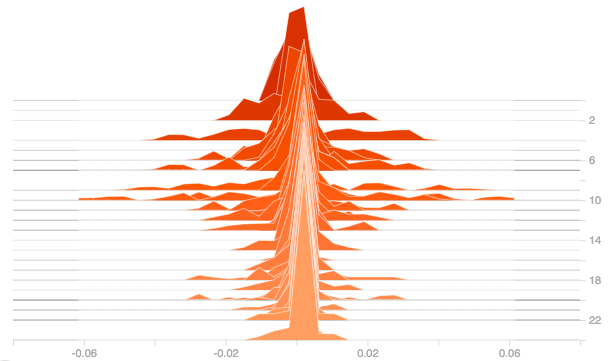
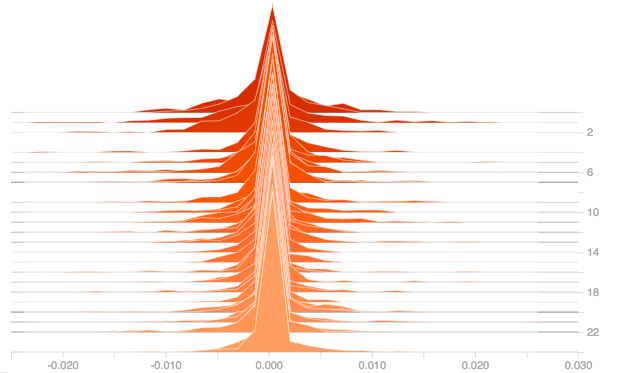
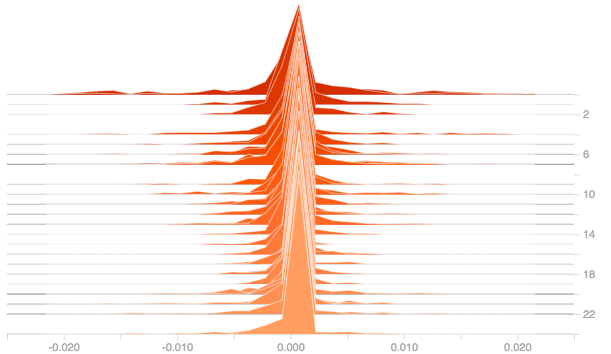
From the above plots it can be observed that weight initialization has no much effect. From the plots of he_normal, he_uniform and lecun_normal, it could be observed that there is slight improvement in the initial stage but as the epochs increased, the derivatives got pulled towards zero.
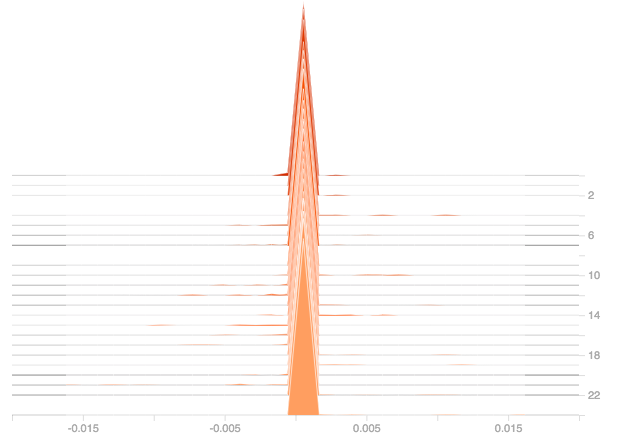
Since the input is highly negative, will initialize the weights also to negative values using:

Here the weights are assigned values uniformly random between -1 and 0, which is the same distribution as that of the input and the plot of gradients and output is given below:
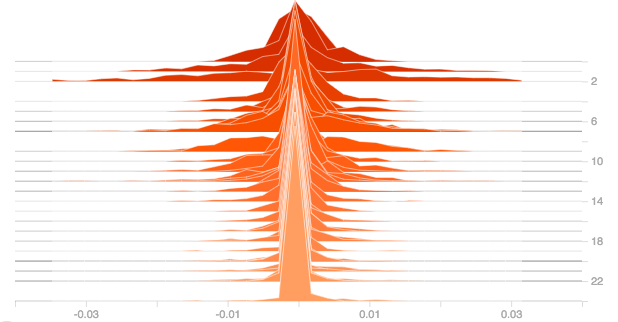
The same can be observed here also, as the epochs increased, the gradients became zero and the output also got pulled towards zero. So changing the initial weights could be considered as an option while dealing with Dead ReLU, however care must be taken to ensure that the model doesn’t run for too many epochs as it will further lead to the issue of ReLU dying. Infact, changing the initial weights don’t have much impact anyway which is clear from the above plots.
6.Does changing activations help?
This may help. So what are the alternatives to ReLU? We can always use tanh and Sigmoid activations. Using a modified version of ReLU called Leaky ReLU, can also help get around the problem. However, in the particular example created for this experiment, all the mentioned activations fail because they suffer from Vanishing Gradients. When we consider the tradeoff between Vanishing gradients and Dying ReLU, it’s always better to have something than nothing. In Vanishing gradients, there is some learning, but in the case of dead ReLU there is no learning, the learning is halted.
An improved version of Leaky ReLU called SELU(Scaled Exponential Linear Units) comes to the rescue. SELU activation self normalizes the Neural Networks, which means the network will have a mean of 0 and variance of 1 for its weights and bias after normalization. The main advantage of SELU is that it doesn’t suffer from Vanishing Gradients and Exploding gradients and also does not lead to dead activations. For more on SELU, refer to this paper. Note: SELU must be used with lecun_normal initialization and AlphaDropout as dropout. For the above dataset, use the following network with SELU activation :
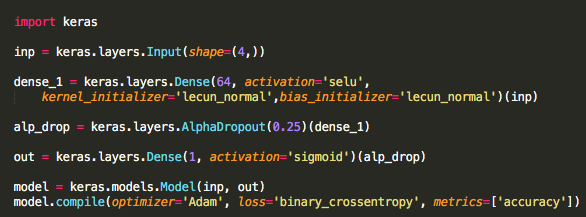
Now Plotting the Gradients and the Output of the Dense Layer :
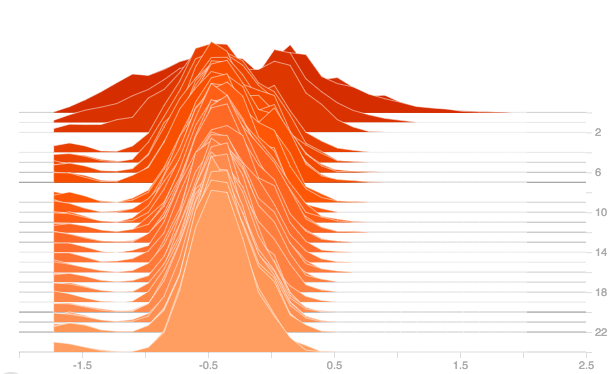
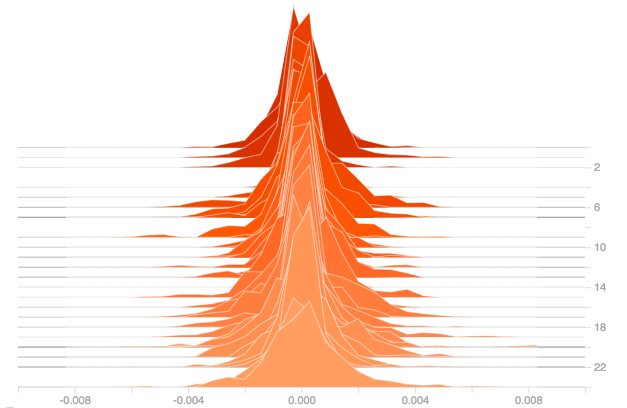
From the plot of gradients, it can be observed that the gradients have improved, the gradients are being pulled away from zero. And from the plot of outputs, it can be seen that the output of the dense layer with SELU activation is small but not zero like the above case. So even for this worst case, SELU does a good job than ReLU.
Conclusion:
It is always a good practice to monitor the loss and gradients while working with Deep Neural Networks. This could help identify most of the issues related to training a Deep Learning model. There is no point in coding deep networks if you don’t know how to identify problems and debug them. This article is just a needle in a haystack. There are more problems associated with training Deep Neural Networks. Everyone who works with Deep Learning and Artificial Neural Networks would have faced this problem once in a while. If proper care not taken, then wasting hours retraining the model by changing the model’s parameters is useless. Since ReLU is the most preferred Activation function for most of the Deep Learning problems, care should be taken to avoid this problem. Thanks to TensorBoard, it’s now possible to identify this issue easily.