AI Controlling Car in GTA San Andreas
Objective :
The Objective of the project is to use Artificial Intelligence to drive a car automatically in GTA San Andreas game.
Introduction :
Machine learning models can learn a lot from most of the gaming environment especially considering the fact that most of the modern day games are more realistic and they resemble that of the real world. For this problem I chose GTA San Andreas game. The reason why I chose this game is because the traffic and roads resemble that of a real world situation. There are high traffic areas, low traffic areas and also people walking in the streets and also different weather conditions and also there is night and day time, which is perfect for training a machine learning model.
Inputs :
The inputs to the model are visual data along with the directional key pressed in each frame. A 35 minute video of gameplay recorded at 30 fps along with the directional key pressed in each frame are the inputs. However GTA game is more than about driving a car, for this specific problem I used the information of driving the car around various regions of GTA San Andreas that are accessible. In this game, a minute = 1 hour in real time. So I used 35 minute gameplay so I could get both night as well as day time.
Output :
The output from the model is the key to be pressed. There are 9 possible key combinations possible while driving a car in game they are : U(UP),D(Down),L(Left),R(Right), None and combinations of them they are: LU,LR,DL and DR. So totally we have 9 different classes which the model should learn and output.
Model Used:
The first algorithm that comes into mind when hearing about Image classification is Convolutional Neural Network. For this one too I used a CNN model. However building a CNN model from scratch for this project is expensive cos there are around 70k image frames and it takes too much time to train a model. So I used Transfer learning using an Inception-V3 model for the same. Transfer Learning involves using a pre-trained neural network.
Inception V3:
Inception model is widely used in the area of image recognition. Inception model consists of 2 parts namely : Feature Extraction part with Convolutional Neural Networks and Classification using fully connected and softmax layers. The high level architecture of an inception net is given below.
](https://res.cloudinary.com/jithinjayan1993/image/upload/v1595086319/gta-sa/1_nJ6IoHRvG_MSVIfxfRy2Ug_baxze8.png)
Inception Model includes Convolutions, Average Pooling, max pooling, concatenations, dropouts and fully connected layers. Loss is computed via Softmax. However for this problem I do not use the classification part of Inception Model. The inception model used in this work is a Inception network that has been pre-trained on the imagenet dataset.
Experiment Set Up and Modelling:
Step 1: Data collection : The data collected is a 35 minute screen record of the gameplay which is recorded at 30 frames per second. The big challenge here is to get the key pressed in each frame. As mentioned in the above section, that i have 9 classes here. ie there are 9 possible keys that can be pressed in a single frame. So what I did here was along with the gameplay I created a separate frame using open CV which will display the key pressed in each frame along with the gameplay. The code used for this is given below.
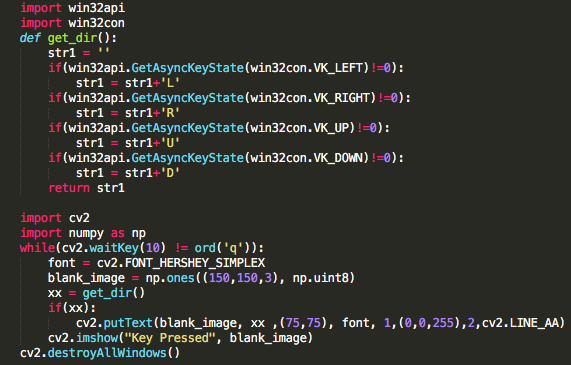
Using the above code, the individual frames looks like this :
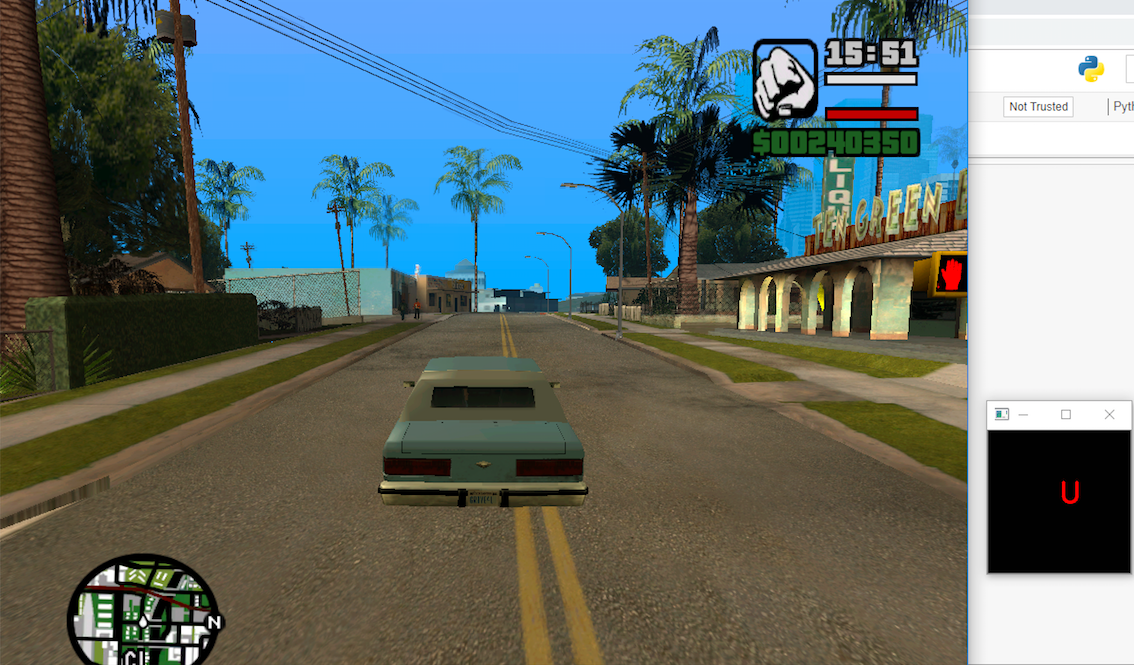 Game Frame along with the key pressed
Game Frame along with the key pressed
The frame contains two parts: The main Gameplay and the key press. Now the question is why did I choose this method? Well the reason is sometime images speak more than words. So if I want to edit the frames or cut some frames, I can still do it easily without the loss of any key press data.
Step 2 :In this step I split the frame into two parts namely image part and then the direction(key) part. Now I cropped the main frame such that some of the invalid information such as sky, time and other information from screen which are not important to me in this problem. The final images look like this :

 Key Press frame separated from the main gameplay frame
Key Press frame separated from the main gameplay frame
Step 3 : This is perhaps one of the most challenging part of the whole project. Extracting the Key pressed in each frame. There are around 70k frames and manually labelling them is troublesome and time consuming. There are state of the art OCR(optical character recognition) techniques such as the Google Tesseract, however it was found to produce not so good result in this case. So the best strategy is to use Convolutional Neural network to advantage. So I collected some of the samples from the key press data and stored them in 9 folders such that each folder contains the same direction. For each of the 9 classes around 250 samples were used.

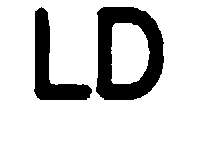

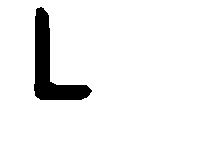


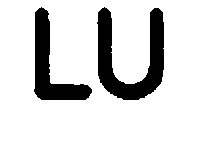

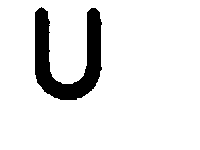
In the above image R = Right, L=Left, U=Up, D = Down LU = Left+Up, Blank = No key Press etc.
Now that I have the labelled data, I built a CNN model.
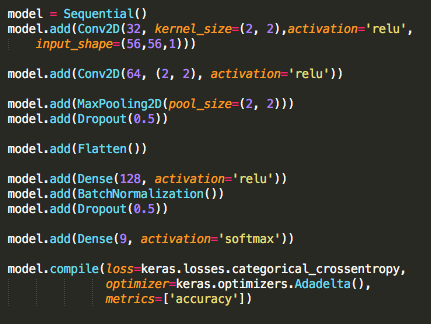
This simple CNN gave an accuracy of 100% on train data and I used the same CNN model to predict the direction for all other Key frames and to my surprise it did a terrific job in detecting the key press in each frame. Now the big question is does my model overfit? well it’s okay even if the model overfit since I am using this model only for this particular sub problem.
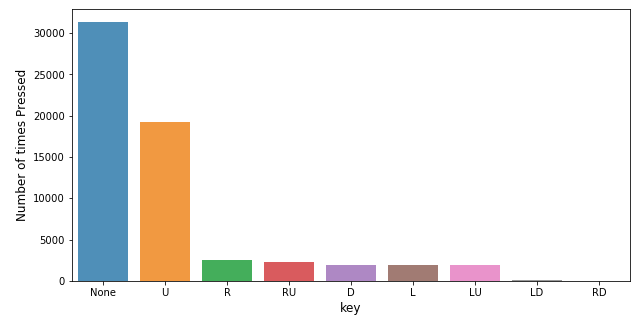
This data has an imbalanced distribution. So it should be taken care to avoid the model from being overfitted.
Step 4 : Now that I extracted the key press information in each frame, I can go for the actual Modelling. As mentioned earlier an Inception V3 model is used.
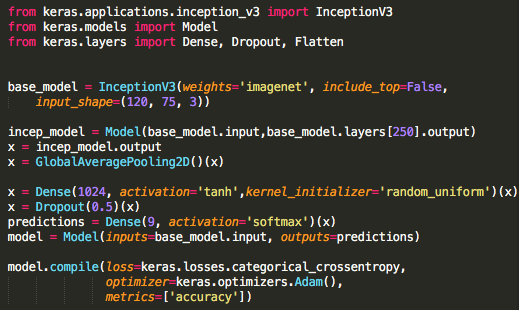
Here I used 250 layers of Inception model and setting the size of input images to (120,75,3), 3 because the number of channels in a colour image is 3. I set include_top = False which means I don’t use the classification layers at the top. On the output of Inception model, I apply a Global Average pooling which is similar to 2D Average Pooling block except that the pool size is the size of the entire input of the block ie it computes a single average value for the all the incoming data. And on this output I applied a Dense layer with 1024 neurons and with tanh activation function. Loss function used is Categorical Cross Entropy with Optimizer as Adam. Early stopping with a patience of 15 was used to avoid the model from overfitting.
Results :
The model has a validation accuracy of 99.035 on the train dataset. But the dataset is imbalanced, so I need to confirm that the model hasn’t overfitted. So I need to check the precision and Recall for the model on the train data.
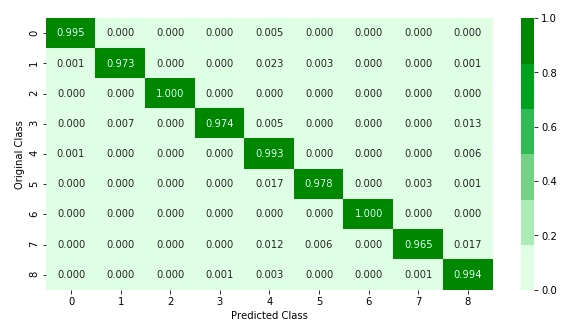
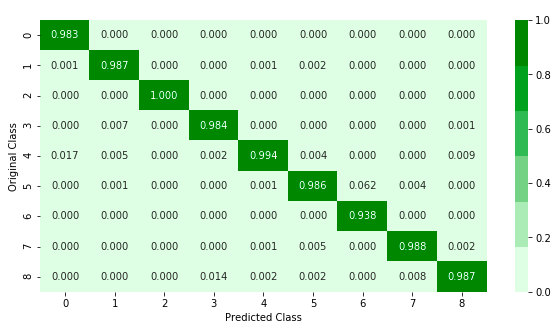
From the Recall and Precision matrix, it can be observed that the model has done a very good job to identify the 9 different classes despite the fact that the dataset is imbalanced.
Now Testing the model on a completely different scene which the model hasn’t seen.
In the video, The red is the actual key pressed and the blue in main screen is the predicted key. Some of the Observations are:
-
The Predicted key is same in most cases as that of the actual key pressed which implies that the model is not overfitting.
-
The model has learned to stop at red signal.
-
The model can drive at night.
Some Failure Cases :
- Driving in Extreme Conditions
For this test I made the model run in the background and gave the control of the car to the model. The climate here is night and snowy and the visibility is nearly zero and model struggles to drive the car well here. Whenever there is a key name appear on the black frame, it means I helped the model there and the key that I pressed is displayed there. It can be very clearly seen from the video that the model struggles to drive when visibility is nearly zero.
- Steep turns
Just like the above case(Video 2) model controls the car, however when model struggles, I help the model by pressing keys manually which can be seen in the black frame the key I pressed. One major observation is that when there is a very steep turn model faces difficulty to turn properly. This issue can be resolved if the duration of key press is also considered during the training.
Comparison With Need For Speed Undercover :
I trained Inception model using the similar approach as above on NFS Undercover game. In the video the one in main frame(blue colour text) is the predicted key and the text in black frame is the actual key pressed. However it can be seen from the video that the model doesn’t do a very good job here the reason for that is because the traffic in NFS is less compared to that of the GTA game. Also the model was having an accuracy of only 84% while training. However this could be improved if more data was used for training. The code is available in my GitHub account.
Future Work :
-
Could use other models as base learners in transfer learning such as AlexNet, VGG16, Resnet, Densenet etc.
-
Even though I tried the same with Need For Speed Undercover, the results were biased because the traffic was very less compared to that of GTA. However considering more data during training might improve the results.
-
Same can be tried with latest versions of GTA as they are more realistic than this version.
-
Including in training data different climatic conditions when the visibility is very less.
References :
The following are some of the references I used for this work:
-
https://github.com/tensorflow/models/tree/master/research/inception
-
https://codelabs.developers.google.com/codelabs/cpb102-txf-learning/index.html#1
-
https://www.tensorflow.org/beta/tutorials/images/transfer_learning
-
https://sites.google.com/a/princeton.edu/arturf/self-driving-and-gta5